рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Типы баз данных
Реферат Курсовая Конспект
Типы баз данных
Типы баз данных - раздел Образование, РАБОТА С БАЗАМИ ДАННЫХ Наиболее Широко Распространенными Являются Иерархические, Сетевые И ...
Наиболее широко распространенными являются иерархические, сетевые и реляционные модели данных, каждая из которых имеет свою внутреннюю схему построения. Соответствующим образом называют и СУБД, поддерживающие перечисленные модели.
В иерархических БД данные представляются в виде древовидной структуры (см. рис.1). Дерево представляет собой иерархию элементов, называемых узлами. На самом верхнем уровне иерархии имеется только один узел - корень. Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называемом исходным узлом для данного узла. Ни один элемент не имеет более одного исходного. Каждый элемент может быть связан с одним или несколькими элементами на более низком уровне. Они называются порожденными. Иерархическая база данных, как правило, состоит из совокупности таких «деревьев», которые образуют множество деревьев, или «лес».
Иерархические БД обладают высокой скоростью доступа к требуемой информации в направлении от основания дерева к его вершинам, однако, с другой стороны, затрудненным доступом к информации в обратном направлении - от периферии к основанию дерева.
 |
Рис.1. Схематическое изображение иерархической БД
Если порожденный элемент в отношении между данными имеет более чем один исходный элемент, то это отношение, очевидно, уже нельзя описать как древовидную структуру. Его описывают в виде сетевой структуры (см. рис. 2).
 |
Рис. 2. Схематическое изображение сетевой БД
Каждый элемент в сетевой структуре может быть связан с любым другим элементом. Такие структуры используются для представления данных в сетевых СУБД. В сетевых моделях снимается указанный выше недостаток иерархических БД, однако, с другой стороны, язык манипулирования данными для таких моделей всегда является гораздо более сложным, так как содержит большое число разнотипных команд и слабо формализуется.
В настоящее время на персональных компьютерах наиболее распространены т.н. реляционные модели БД. В основе реляционной модели данных лежит понятие отношения, или реляции (relation – отношение, англ., отсюда и происходит термин реляционные БД). Отношение удобно и наглядно представляется в виде двумерной (плоской) таблицы при соблюдении определенных ограничивающих условий. Данные в таблицах могут быть связанными, а сама реляционная база данных представляет собой набор таких взаимосвязанных таблиц.
В реляционных БД (РБД) все объекты разделяются на типы, т.е. каждый объект относится к некоторому типу. Объекты одного и того же типа имеют свой, соответствующий их типу, набор атрибутов. Поэтому объекты одного типа в РБД представляются записями с одинаковым количеством полей, а каждый экземпляр объекта можно представить как вектор с соответствующим количеством измерений. Например, если n – количество атрибутов объекта данного типа, то i-й экземпляр объекта можно представить как вектор Аi=(Ai1,Ai2,…,Ain). Вся совокупность из m экземпляров объектов данного типа может быть представлена в виде матрицы или таблицы размерностью m*n вида
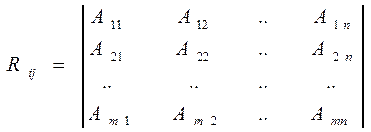 |
Множество строк в таблице Rij, т.е. экземпляров объекта данного типа, и называется отношением, а совокупность всех возможных значений таблицы Rij называется схемой отношений.
В зависимости от содержания в РБД различают два типа отношений: объектные и связные. Объектное отношение хранит данные об объектах и отражает зависимости между атрибутами объекта, связное отношение отражает зависимости между отдельными таблицами в РБД.
В объектном отношении один из атрибутов однозначно идентифицирует объект в таблице, т.е. запись в таблице, а именно каждому конкретному значению такого атрибута будет соответствовать одна и только одна запись (строка) в таблице. Понятно, что значения такого атрибута в столбце таблицы должны быть уникальны и никогда не повторяться. Такой атрибут называется первичным ключом отношения. Для удобства первичный ключ обычно размещают в первом столбце таблицы. Для обеспечения уникальности значения первичного ключа, если в таблице нет одного атрибута с неповторяющимися значениями, такой ключ может состоять из нескольких атрибутов, и тогда он называется составным ключом.
В связном отношении атрибуты-признаки разных таблиц используются для организации связей между таблицами. Благодаря наличию таких связей обеспечивается целостность БД и взаимодействие данных, содержащихся в различных таблицах БД.
Реляционную модель данных предложил в 1969 году Э.Ф. Кодд – сотрудник фирмы IBM. Основной принцип реляционного подхода заключается в использовании операций над таблицами, а не над отдельными записями, что имеет место в иерархических и сетевых БД. Можно выделить следующие важные преимущества РБД:
· отношения (таблицы) не зависят от способа хранения данных в компьютере;
· теория отношений является областью математической логики, т.н. реляционной алгебры, и поэтому хорошо формализована;
· имеется простой и единообразный способ представления данных в виде таблиц;
· осуществляется надежное обеспечение целостности и защиты данных и некоторые другие.
Важным достоинством реляционной модели данных является то, что на основе уже имеющихся схем отношений можно получать новые схемы, которые ранее в файле базы данных не были представлены. Таким способом соответствующая СУБД позволяет получать ответы на незапланированные прикладными программами информационные запросы.
Необходимо отметить, что РБД не лишены и определенных недостатков: медленность работы для больших БД, жесткость структуры данных и некоторые другие. Однако для персональных компьютеров и не очень больших БД в настоящее время используются исключительно реляционные модели БД.
Итак, перечислим исходные компоненты реляционной модели данных, основанной на совокупности отношений:
· все множество объектов (записей) предметной области, которую описывает БД, разделяется на несколько типов, каждый из которых представляется своей таблицей;
· каждому типу объектов соответствует определенный набор атрибутов, который определяет содержание соответствующей данному типу объектов таблице;
· каждый тип объектов имеет свои признаки или характеристики – атрибуты, значения которых содержатся в полях – в столбцах таблицы;
· каждому конкретному объекту данного типа соответствует определенный набор значений этих атрибутов, соответствующий строке в таблице;
· атрибут (или набор атрибутов), однозначно определяющий объект в таблице (т.е. строку в таблице), называется первичным ключом объекта;
· в таблицах имеются также атрибуты, являющиеся первичными ключами в других таблицах, т.н. внешние ключи, которые обеспечивают связь между таблицами в РБД.
1.2. Нормализация отношений в РБД
Самым простым примером РБД является база данных, состоящая всего из одного отношения – одной таблицы. Однако в таком случае, как правило, не будут выполняться основные требования, предъявляемые к структуре БД из-за возникающих проблем избыточности информации, нарушения целостности данных, сложности редактирования данных, низкой скорости обработки информации и т.п. Убедимся в этом на конкретном примере небольшой БД, основанной на одной таблице «Поставки товаров», в которой будем хранить сведения о товарах, их цене, количестве и стоимости, а также о поставщиках, их адресах и расчетных счетах. Предположим, что эти данные будут храниться в следующей таблице (здесь приведены только первые четыре записи и всего 7 полей, хотя в реальной БД их число будет неизмеримо большим):
| Товар | Цена | Кол-во | Стоимость | Поставщик | Адрес | Счет |
| Стол | Пинскдрев | 226000, Брестская обл., г. Пинск | ||||
| Стул | Орбита | 220111, Минская обл., г. Слуцк | ||||
| Кресло | Столиндрев | 226100, Брестская обл., г. Столин | ||||
| Диван | Пинскдрев | 226000, Брестская обл., г. Пинск | ||||
Анализируя структуру таблицы, необходимо прежде всего отметить, что в ней имеется повторяющаяся информация о поставщике. Кроме того, стоимость товара является избыточной информацией, так как всегда может быть получена на основе цены товара и его количества. Далее, атрибуты «Адрес» и «Счет» характеризуют только поставщика и, вообще говоря, не связаны с поставляемым товаром. Существуют и другие более тонкие недостатки в структуре такой БД.
Таким образом, на первом этапе проектирования РБД важнейшим является вопрос, какую выбрать схему отношений для данной БД из множества альтернативных вариантов, т.е. какую систему таблиц и с каким набором столбцов в каждой таблице выбрать для данной БД. Как правило, БД содержат объекты разных типов и для каждого типа объектов создается своя таблица с соответствующим набором столбцов-атрибутов объекта.
Процесс создания оптимальной схемы отношений для РБД строго формализован и называется нормализацией БД. Нормализация – это формализованная процедура, в процессе выполнения которой атрибуты данных группируются в таблицы, а таблицы, в свою очередь, в БД.
Цели нормализации следующие:
· исключить дублирование информации;
· исключить избыточность информации;
· обеспечить возможность проведения непротиворечивых и корректных изменений данных в таблицах;
· упростить и ускорить поиск информации в БД.
Процесс нормализации состоит в приведении таблиц РБД к т.н. нормальным формам. Всего существует 5 нормальных форм, которые удовлетворяют соответствующим правилам нормализации. При этом в большинстве случаев оптимальная структура БД достигается при выполнении уже первых 3 правил нормализации, которые были сформулированы для РБД Э.Ф. Коддом в 1972 году.
Чтобы таблица, а вместе с ней и БД, соответствовала 1-й нормальной форме, необходимо, чтобы все значения ее полей были атомарными (неделимыми) и невычисляемыми, а все записи – уникальными (не должно быть полностью совпадающих строк). Выполняя это правило, преобразуем первоначальную таблицу к виду
| Товар | Цена | Кол-во | Поставщик | Индекс | Область | Город | Счет |
| Стол | Пинскдрев | Брестская | Пинск | ||||
| Стул | Орбита | Минская | Слуцк | ||||
| Кресло | Столиндрев | Брестская | Столин | ||||
| Диван | Пинскдрев | Брестская | Пинск | ||||
Чтобы таблица соответствовала 2-й нормальной форме, необходимо, чтобы она уже находилась в 1-й нормальной форме и все неключевые поля полностью зависели от ключевого. В данной таблице на роль ключевого поля может претендовать только поле (атрибут-признак) «Товар», значения которого в таблице не повторяются. Из других полей только поле «Поставщик» непосредственно связано с поставляемым товаром – полем «Товар», а поля «Индекс», «Область», «Город» и «Счет» характеризуют только самого поставщика. Поэтому, удовлетворяя 2-му правилу нормализации, необходимо разбить (или разложить) исходную таблицу на две – соответственно «Товары»
| Товар | Цена | Количество | Поставщик |
| Стол | Пинскдрев | ||
| Стул | Орбита | ||
| Кресло | Столиндрев | ||
| Диван | Пинскдрев | ||
и «Поставщики»
| Поставщик | Индекс | Область | Город | Счет |
| Пинскдрев | Брестская | Пинск | ||
| Орбита | Минская | Слуцк | ||
| Столиндрев | Брестская | Столин | ||
Проведенное преобразование называется разложением, или проектированием, БД и является обратимой операцией. Причем проектирование исходной таблицы привело, с одной стороны, к уменьшению записей (строк) во второй таблице, однако, с другой стороны, для организации связей между отдельными таблицами и обеспечения таким образом целостности БД поле «Поставщик» появилось уже в обеих таблицах, привнося этим некоторую неизбежную избыточность информации в БД. Очевидно, что в больших БД, где реально существуют сотни и тысячи записей, эта избыточность во много раз будет перекрыта уменьшением общего размера таблиц, полученных из исходной таблицы при ее разложении.
Заметим, что на роль ключевого поля таблицы «Поставщики» подходит поле «Поставщик», значения которого в этой таблице уже не повторяются. Можно отметить, что на эту роль вполне подходит и поле «Счет», значения которого также не будут повторяться, а само поле, хотя и выглядит как набор цифр, все же является не количественной, а качественной характеристикой объекта, т.е. является атрибутом-признаком, что необходимо для ключевого поля (см. выше).
Чтобы теперь перейти к 3-й нормальной форме, необходимо прежде всего обеспечить, чтобы все таблицы БД находились во 2-й нормальной форме и все неключевые поля в таблицах зависели только от ключа таблицы и не зависели непосредственно друг от друга. Анализируя таблицу «Поставщики», можно заметить, что поля «Область» и «Город» являются зависимыми от поля «Индекс», и поэтому эта таблица не находится в 3-й нормальной форме. В связи с этим, необходимо разбить таблицу на две: оставить в таблице «Поставщики» только два «Поставщик» и «Счет», а также поле «Индекс» для обеспечения связи между таблицами,
| Поставщик | Индекс | Счет |
| Пинскдрев | ||
| Орбита | ||
| Столиндрев | ||
а остальные поля выделить в новую таблицу «Адреса»,
| Индекс | Область | Город |
| Брестская | Пинск | |
| Минская | Слуцк | |
| Брестская | Столин | |
в которой поле «Индекс», естественно, будет ключевым, так как его значения в таблице не повторяются.
Приведение БД к 4-й и 5-й нормальным формам является необходимой операцией в специальных случаях, когда между элементами БД существуют связи типа многие-ко-многим (см. ниже) и при этом необходимо обеспечить возможность точного восстановления исходной таблицы из таблиц, на которые она была спроектирована. Как уже говорилось выше, этими правилами нормализации при проектировании БД в большинстве случаев можно пренебречь.
– Конец работы –
Эта тема принадлежит разделу:
РАБОТА С БАЗАМИ ДАННЫХ
БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНОЛОГИЧЕСКИЙ УНИВЕРСИТЕТ... Кафедра информатики и вычислительной техники...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Типы баз данных
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?
Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.022 сек.
Новости и инфо для студентов