Общее назначение - раздел Математика, Доклады по дисциплине Дополнительные главы математической статистики . Регрессионный анализ. 4 Любой Закон Природы Или Общественного Развития Может Быть Выражен В Конечном ...
Любой закон природы или общественного развития может быть выражен в конечном счете в виде описания характера или структуры взаимосвязей (зависимостей), существующих между изучаемыми явлениями или показателями (переменными величинами или просто переменными). Если эти зависимости:
а) стохастичны по своей природе, т. е. позволяют устанавливать лишь вероятностные логические соотношения между изучаемыми событиями А и В, а именно соотношения типа «из факта осуществления события А следует, что событие В должно произойти, но не обязательно, а лишь с некоторой (как правило, близкой к единице) вероятностью Р»;
б) выявляются на основании статистического наблюдения за анализируемыми событиями или переменными, осуществляемого по выборке из интересующей нас генеральной совокупности,
то мы оказываемся в рамках проблемы статистического исследования зависимостей. Соответствующий математический аппарат, будучи таким образом нацеленным в первую очередь на решение основной проблемы естествознания: как по отдельным, частным наблюдениям выявить и описать интересующую нас общую закономерность? — занимает, бесспорно, центральное место во всем прикладном математическом анализе.
— так называемые входные переменные, описывающие условия функционирования (часть из них, как правило, поддается регулированию или частичному управлению); в соответствующих математических моделях их называют независимыми, факторами-аргументами, экзогенными, предикторными (или просто предикторами, т. е. предсказателями), объясняющими;
— выходные переменные, характеризующие поведение или результат (эффективность) функционирования; в математических моделях их называют зависимыми, откликами, эндогенными, результирующими или объясняемыми;
— латентные (т. е. скрытые, не поддающиеся непосредственному измерению) случайные достаточные» компоненты, отражающие влияние (соответственно на ) неучтенных на входе» факторов, а также случайные ошибки в измерении анализируемых показателей (в математических моделях их, как правило, именуют просто «остатками»).
рис.1. Общая схема взаимодействия переменных при статистическом исследовании зависимостей
Тогда общая задача статистического исследования зависимостей (в терминах изучаемых показателей) может быть сформулирована следующим образом:
по результатам n измерений исследуемых переменных на объектах (системах, процессах) анализируемой совокупности построить такую (векторнозначную) функцию
,
которая позволила бы наилучшим (в определенном смысле) образом восстанавливать значения результирующих (прогнозируемых) переменных по заданным значениям объясняющих (предикторных) переменных .
Данная формулировка задачи нуждается в уточнениях. В частности, прежде всего мы должны ответить на следующие вопросы:
а) каково математическое выражение (или структура модели) искомой зависимости между X и Y, записанное в терминах X, Y, f(X) и ;
б) в соответствии с каким именно критерием качества аппроксимации значений Y с помощью функции f(X) мы будем определять наилучший способ восстановления значений результирующих показателей по заданным значениям объясняющих переменных?
в) с какой именно прикладной целью мы проводим все наше исследование, т. е. для решения каких конкретных задач собираемся использовать построенную в результате исследовании функцию f(X)?
Рассмотрим общую схему. Пусть значение исследуемого результирующего показателя при данных фиксированных величинах объясняющих переменных случайным образом флюктуирует вокруг некоторого (вообще говоря, неизвестного) уровня , зависящего от конкретных значений предикторов , т. е. , где остаточная компонента определяет случайное отклонение значения от постоянного (при фиксированных ) уровня f. При этом наличие флюктуации может быть присуще самой природе эксперимента или наблюдения, а может объясняться случайными ошибками в измерении величины f (тогда является результатом несколько искаженного измерения значения f). Когда говорят, что «некоторая величина () случайным образом флюктуирует вокруг определенного (неслучайного) уровня f», то, как правило, имеют в виду, что среднее значение такой флюктуирующей случайной величины должно быть равно f, т. е. . Поскольку условия эксперимента и, в частности, уровень, около которого флюктуирует , зависят от конкретных значений некоторого набора объясняющих переменных, соответственно , то . Функция , описывающая зависимость условного среднего значения результирующего показателя (вычисленного при условии, что величины предсказывающих переменных зафиксированы на уровнях ) от заданных фиксированных значений предсказывающих переменных, называется функцией регрессии.
Происхождение термина «регрессия» (лат. «regression» — отступление, возврат к чему-либо) связано только с прикладной спецификой одного из первых конкретных примеров, в котором это понятие было использовано, но никак не с его общесмысловым наполнением. Этот термин был введен английским психологом и антропологом Ф. Гальтоном в связи с вопросом о наследственности роста. Обрабатывая статистические данные, Гальтон нашел, что сыновья отцов, отклоняющихся по росту на л- дюймов от среднего роста всех отцов, сами отклоняются от среднего роста всех сыновей меньше, чем на х дюймов. Гальтон назвал выявленную тенденцию «регрессией к среднему состоянию» («regression to mediocrity»).
Иногда, при проведении анализа линейной модели, исследователь получает данные о ее неадекватности. В этом случае, его по-прежнему интересует зависимость между предикторными переменными и откликом, но для уточнения модели в ее уравнение добавляются некоторые нелинейные члены. Самым удобным способом оценивания параметров полученной регрессии является Нелинейное оценивание. Например, его можно использовать для уточнения зависимости между дозой и эффективностью лекарства, стажем работы и производительностью труда, стоимостью дома и временем, необходимым для его продажи и т.д. На самом деле Нелинейное оценивание можно считать обобщением методов множественной регрессии и дисперсионного анализа. Так, в методе множественной регрессии (и в дисперсионном анализе) предполагается, что зависимость отклика от предикторных переменных линейна. Нелинейное оценивание оставляет выбор характера зависимости за вами. Например, вы можете определить зависимую переменную как логарифмическую функцию от предикторной переменной, как степенную функцию, или как любую другую композицию элементарных функций от предикторов.
Если позволить рассмотрение любого типа зависимости между предикторами и переменной отклика, возникают два вопроса. Во-первых, как истолковать найденную зависимость в виде простых практических рекомендаций. С этой точки зрения линейная зависимость очень удобна, так как позволяет дать простое пояснение: “чем больше x (т.е., чем больше цена дома), тем больше y (тем больше времени нужно, чтобы его продать); и, задавая конкретные приращения x, можно ожидать пропорциональное приращение y”. Нелинейные соотношения обычно нельзя так просто проинтерпретировать и выразить словами. Второй вопрос - как проверить, имеется ли на самом деле предсказанная нелинейная зависимость.
Содержание... Регрессионный анализ Теоретическая часть работы...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ:
Общее назначение
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
Виды регрессионного анализа
Многошаговая регрессия (ШРА) — последовательность шагов РА, выполняемая в направлении увеличения или уменьшения количества учитываемых коэффициентов линейной модели регрессии.
Линейная регрессия
Регрессионный анализ - раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным. Проблема
Описание объекта
В нашем случае объектом исследования является совокупность наблюдений за посещаемостью WEB сайта Комитета по делам семъи и молодежи Правительства г. Москвы www.telekurs.ru/ismm. Тематика сайта – эт
Факторы формирующие моделируемое явление
Отбор факторов для модели осуществляется в два этапа. На первом идет анализ, по результатам которого исследователь делает вывод о необходимости рассмотрения тех или иных явлений в качестве переменн
Построение уравнения регрессии
Используя программное обеспечение «ОЛИМП» (которое в свою очередь использует для расчетов указанные выше принципы и формулы чем значительно облегчает нам жизнь), найдем искомое урав
Смысл модели
При увеличении количества вакансий в день, количество посетивших сайт людей будет увеличиваться . Это означает что в настоящий момент сайт не полностью удовлетворяет запросы пользователей, что необ
Оценивание линейных и нелинейных моделей
Формально говоря, Нелинейное оценивание является универсальной аппроксимирующей процедурой, оценивающей любой вид зависимости между переменной отклика и набором независимых переменных. В общ
Регрессионные модели с линейной структурой
Полиномиальная регрессия. Распространенной “нелинейной” моделью является модель полиномиальной регрессии. Термин нелинейная заключен в кавычки, поскольку эта модель линейна
Существенно нелинейные регрессионные модели
Для некоторых регрессионных моделей, которые не могут быть сведены к линейным, единственным способом для исследования остается Нелинейное оценивание. В приведенном выше примере для скорости
Регрессионные модели с точками разрыва
Кусочно - линейная регрессия. Нередко вид зависимости между предикторами и переменной отклика различается в разных областях значений независимых переменных. Например,
Методы нелинейного оценивания
Метод наименьших квадратов Функция потерь Метод взвешенных наименьших квадратов Метод максимума правдоподобия Максимум правдоподобия и логит/пробит мод
Начальные значения, размеры шагов и критерии сходимости.
Общим моментом всех методов оценивания является необходимость задания пользователем некоторых начальных значений, размера шагов и критерия сходимости алгоритма. Все методы начинают свою работу с ос
Оценивание пригодности модели
После оценивания регрессионных параметров, существенной стороной анализа является проверка пригодности модели в целом. Например, если вы определили линейную регрессионную модель, а реальная зависим
Распределения Вейбулла - Гнеденко
Экспоненциальные распределения - частный случай так называемых распределений Вейбулла - Гнеденко. Они названы по фамилиям инженера В. Вейбулла, введшего эти распределения в практику анализа результ
Распределение Рэлея
Распределение Рэлея введено Дж. У. Рэлеем (1880) в связи с задачей сложения гармонических колебаний со спиральными фазами. Закон Рэлея применяется для описания неотрицательных величин, в частности,
Факторный анализ как метод редукции данных
Под редукцией понимается переход от многих исходных количественных признаков к пространству факторов, число которых значительно меньше числа исходных количественных признаков. Например, от исходных
Общий обзор методов факторного анализа
В основе каждого метода факторного анализа лежит математическая модель, описывающая соотношения между исходными признаками и обобщенными факторами. Перейдем к краткой характеристике этих моделей дл
Метод главных компонент
В основе модели для выражения исходных признаков через факторы здесь лежит предположение о том, что число факторов равно числу исходных признаков (k=m), а характерные факторы вообще отсутств
Центроидный метод
Этот метод основан на предположении о том, что каждый из исходных признаков aj(j = 1...m) может быть представлен как функция небольшого числа
общих факторов F1
Метод экстремальной группировки параметров
Данный метод также основан на обработке матрицы коэффициентов корреляции между исходными признаками. В основе этого метода лежит гипотеза о том, что совокупность исходных признаков может быть разби
Критерии рационального выбора числа факторов
Сколько факторов следует выделять?Напомним, что анализ главных компонент является методом сокращения или редукции данных, т.е. методом сокращения числа переменных. Возникает естест
Проверка качественных характеристик выборки
Будем рассматривать критерии однородности.
Любой статистически критерий проверки гипотез представляет собой средство измерения. Поэтому пользоваться им следует также квалифицированно, как
Метод минимального расстояния
Равномернаяметрика,или метрика Колмогорова, - одна из наиболее старых и наиболее часто используемых вероятностных метрик. Термин «метрика Колмогорова» в отечественной литературе ис
Проверка количественных характеристик выборки
В §1 были определены характеристики генеральной совокупности, т.е. принадлежность к одной генеральной выборке, а также среднее и первый момент.
На данном этапе имеется функция распределени
Иерархические методы кластерного анализа
Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров в большие или разделении больших кластеров на меньшие.
Иерархические аглом
Меры сходства
Для вычисления расстояния между объектами используются различные меры сходства (меры подобия), называемые также метриками или функциями расстояний.
Для придания больших весов более отдале
Методы объединения или связи
Когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами определяются выбранной мерой. Возникает следующий вопрос — как определить расстояния между кластерами? С
Иерархический кластерный анализ в SPSS
Рассмотрим процедуру иерархического кластерного анализа в пакете SPSS (SPSS). Процедура иерархического кластерного анализа в SPSS предусматривает группировку как объектов (строк матрицы данных), т
Определение количества кластеров
Существует проблема определения числа кластеров. Иногда можно априорно определить это число. Однако в большинстве случаев число кластеров определяется в процессе агломерации/разделения множества об
Итеративный процесс.
Вычисляются центры кластеров, которыми затем и далее считаются покоординатные средние кластеров. Объекты опять перераспределяются.
Процесс вычисления центров и перераспределения объектов п
Проверка качества кластеризации
После получений результатов кластерного анализа методом k-средних, следует проверить правильность кластеризации (т.е. оценить, насколько кластеры отличаются друг от друга). Для этого рассчитывают
Алгоритм BIRCH
(Balanced Iterative Reducing and Clustering using Hierarchies)
Алгоритм предложен Тьян Зангом и его коллегами.
Благодаря обобщенным представлениям кластеров, скорость кластеризаци
Алгоритм WaveCluster
WaveCluster представляет собой алгоритм кластеризации на основе волновых преобразований . В начале работы алгоритма данные обобщаются путем наложения на пространство данных многомерной решетки. Н
Алгоритмы Clarans, CURE, DBScan
Алгоритм Clarans (Clustering Large Applications based upon RANdomized Search) формулирует задачу кластеризации как случайный поиск в графе. В результате работы этого алгоритма совокупность узлов гр
Многофакторный дисперсионный анализ
Следует сразу же отметить, что принципиальной разницы между многофакторным и однофакторным ДА нет. Многофакторный анализ не меняет общую логику ДА, а лишь несколько усложняет ее, поскольку, кроме у
Биотестирование почвы
Многообразные загрязняющие вещества, попадая в агроценоз, могутпретерпевать в нем различные превращения, усиливая при этом свое токсическое действие. По этой причине оказались необх
Дисперсионный анализ в химии
ДА – совокупность методов определения дисперсности, т. е. характеристики размеров частиц в дисперсных системах. ДА включает различные способы определения размеров свободных частиц в жидких и газовы
Хотите получать на электронную почту самые свежие новости?
Подпишитесь на Нашу рассылку
Наша политика приватности обеспечивает 100% безопасность и анонимность Ваших E-Mail

 — так называемые входные переменные, описывающие условия функционирования (часть из них, как правило, поддается регулированию или частичному управлению); в соответствующих математических моделях их называют независимыми, факторами-аргументами, экзогенными, предикторными (или просто предикторами, т. е. предсказателями), объясняющими;
— так называемые входные переменные, описывающие условия функционирования (часть из них, как правило, поддается регулированию или частичному управлению); в соответствующих математических моделях их называют независимыми, факторами-аргументами, экзогенными, предикторными (или просто предикторами, т. е. предсказателями), объясняющими; — выходные переменные, характеризующие поведение или результат (эффективность) функционирования; в математических моделях их называют зависимыми, откликами, эндогенными, результирующими или объясняемыми;
— выходные переменные, характеризующие поведение или результат (эффективность) функционирования; в математических моделях их называют зависимыми, откликами, эндогенными, результирующими или объясняемыми;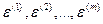 — латентные (т. е. скрытые, не поддающиеся непосредственному измерению) случайные достаточные» компоненты, отражающие влияние (соответственно на
— латентные (т. е. скрытые, не поддающиеся непосредственному измерению) случайные достаточные» компоненты, отражающие влияние (соответственно на 
 исследуемых переменных на объектах (системах, процессах) анализируемой совокупности построить такую (векторнозначную) функцию
исследуемых переменных на объектах (системах, процессах) анализируемой совокупности построить такую (векторнозначную) функцию ,
, по заданным значениям объясняющих (предикторных) переменных
по заданным значениям объясняющих (предикторных) переменных  .
. ;
;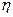 при данных фиксированных величинах объясняющих переменных
при данных фиксированных величинах объясняющих переменных  , зависящего от конкретных значений предикторов
, зависящего от конкретных значений предикторов 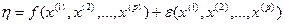 , где остаточная компонента
, где остаточная компонента 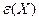 определяет случайное отклонение значения
определяет случайное отклонение значения 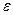 может быть присуще самой природе эксперимента или наблюдения, а может объясняться случайными ошибками в измерении величины f (тогда
может быть присуще самой природе эксперимента или наблюдения, а может объясняться случайными ошибками в измерении величины f (тогда 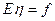 . Поскольку условия эксперимента и, в частности, уровень, около которого флюктуирует
. Поскольку условия эксперимента и, в частности, уровень, около которого флюктуирует  , то
, то  . Функция
. Функция  результирующего показателя
результирующего показателя 





Новости и инфо для студентов