рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Социология
- /
- ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА
Реферат Курсовая Конспект
ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА
ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА - раздел Социология, Глава 7 ...
Глава 7
ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА
ГИПОТЕЗЫ НАУЧНЫЕ И СТАТИСТИЧЕСКИЕ
ПРИМЕР Исходя из теории социального научения, исследователь может предположить, что… Предположение, которое проверяется с применением научного метода, будем называть научной гипотезой.Следует отметить,…ПРИМЕР
 Первым примером применения такой логики для проверки статистической гипотезы, по-видимому, является работа врача королевы Анны, а ранее учителя математики, Дж. Арбутнота «Довод в пользу божественного провидения, выведенный из постоянной регулярности, наблюдаемой в рождении обоих полов» (1710—
Первым примером применения такой логики для проверки статистической гипотезы, по-видимому, является работа врача королевы Анны, а ранее учителя математики, Дж. Арбутнота «Довод в пользу божественного провидения, выведенный из постоянной регулярности, наблюдаемой в рождении обоих полов» (1710—
ЧАСТЬ П. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
1712 гг.)1. В распоряжении Арбутнота были записи о рождении детей на протяжении 82 лет, которые свидетельствовали о том, что за этот период времени каждый год мальчиков рождалось больше, чем девочек. Если исходить из равновероятного рождения мальчиков и девочек (Но: Р= Уг), то вероятность того, что каждый год на протяжении 82 лет мальчиков родится больше, чем девочек, составляет С/2)82 ~ 2-1CT25. Так как эта вероятность очень мала, статистическую гипотезу о равновероятном рождении мальчиков и девочек можно отклонить, приняв альтернативную гипотезу о том, что в действительности вероятность рождения мальчиков достоверно выше У2. Логика обоснования «довода в пользу божественного провидения», предложенная Арбутнотом, в общих чертах сохранилась и по сей день.
ИДЕЯ ПРОВЕРКИ СТАТИСТИЧЕСКОЙ ГИПОТЕЗЫ
Различия действительно обнаружены. Но интуитивно понятно, что такой результат может быть получен случайно, даже если в действительности (в… В нашем примере Но: М} = А, то есть проверяется гипотеза, что среднее… 1 Кендалл М., Стьюарт А. Статистические выводы и связи. С. 687; Гласе Дж., Стэнли Дж. Статистические методы в…In
Формулы, подобные 7.1, позволяют получить так называемое эмпирическое значение критерия для соответствующего теоретического распределения (в данном случае формула 7.1 позволяет вычислить эмпирическое значение z-критерия — для нормального распределения). Подставляя выборочные значения, получаем z — 2. По таблице параметров нормального распределения можно определить, что в диапазоне ±2 находится 0,954 всей площади под кривой. В соответствии с интерпретацией единичной нормальной кривой, этой площади соответствует вероятность того, что случайное отклонение от 0 будет меньше z= ±2. А для нашего случая найденная площадь соответствует вероятности того, что случайное отклонение выборочного среднего значения будет меньше +(МК — А) — ±0,6. Соответственно, вероятность случайного отклонения выборочного среднего от генерального среднего на 0,6 и больше определяется площадью в «хвостах» под кривой нормального распределения — за пределами найденного диапазона (рис. 7.1). Следовательно, вероятность того, что данная выборка принадлежит генеральной совокупности со средним А (то есть, что верна Но), составляет/? = 1 — 0,954 = 0,046. Это и есть вероятность того, что данный выборочный результат мог быть получен случайно, когда на самом деле в генеральной совокупности верна Но или то, что называется р-уровнем значимости.
Следует отметить, что выборочное распределение средних значений соответствует нормальному виду, если N > 100. Для выборок меньшего объема распределение средних начинает зависеть от объема выборок (точнее — от числа степеней свободы, df) и соответствует другому теоретическому распределе-
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
I

Рис. 7.1. Выборочное распределение средних значений для верной Но
нию — /-Стыодента. Тем не менее, общая последовательность проверки статистической гипотезы остается той же, как, впрочем, и для любого другого случая. Сначала вычисляется соответствующее эмпирическое значение:

|
I W _.. А I
df=N-l. (7.2)
Затем вычисленное эмпирическое значение сопоставляется с теоретическим /-распределением для соответствующего числа степеней свободы df. Это позволяет определить /^-уровень — вероятность того, что выборка принадлежит генеральной совокупности, для которой верна нулевая гипотеза Но: М — А.
Таким образом, в основе статистической проверки гипотез лежит представление о теоретическом распределении выборочной статистики — для условия, когда в генеральной совокупности верна нулевая статистическая гипотеза. В исследовании Арбутнота в качестве теоретического выступало биномиальное распределение для Но: Р — '/2, а в нашем примере — распределение выборочных средних для известной нулевой гипотезы (Z-распределение для больших N и /-распределение для малых N). В процессе проверки статистической гипотезы определяется /^-уровень значимости (вероятность того, что нулевая статистическая гипотеза верна) путем соотнесения эмпирических значений выборочных статистик (например, разности средних) с теоретическим распределением, соответствующим нулевой статистической гипотезе.
УРОВЕНЬ СТАТИСТИЧЕСКОЙ ЗНАЧИМОСТИ
ГЛАВА 7. ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА тическая значимость, р-уровень значимости является количественной оценкой… Предположим, при сравнении двух выборочных средних было получено значение уровня статистической значимости/? = 0,05.…СТАТИСТИЧЕСКОЕ РЕШЕНИЕ И ВЕРОЯТНОСТЬ ОШИБКИ
Вполне очевидно, что основанием для принятия исследователем решения о том, какая гипотеза верна, является /^-уровень — вероятность того, что верна… В действительности: Решение н а н истинна Неправильное решение, Правильное решение, ошибка I рода, …ВЫБОР МЕТОДА СТАТИСТИЧЕСКОГО ВЫВОДА
Как уже отмечалось, любая содержательная гипотеза научного исследования касается связи между явлениями (свойствами, событиями) — независимо от… ПРИМЕР______________________________________________________________ … Рассмотрим некоторые возможные способы проверки одной и той же содержательной гипотезы. В одном из исследований…Анализ классификаций
Условие применения: для каждого объекта (испытуемого) выборки определена его принадлежность к одной из категорий (градаций) ^(получено эмпирическое распределение объектов по X); известно теоретическое (ожидаемое) распределение по X(обычно — равномерное).
ПРИМЕР______________________________________________________________
Исследовались различия в предпочтении респондентами пяти политических лидеров. Но: эмпирическое распределение предпочтений респондентов не отличается от равномерного. Таблица сопряженности:
| Полит, лидер (X) | Распределение | |
| Эмпирическое | Теоретическое | |
| Всего: |
Проверяемая Но: эмпирическое (наблюдаемое) распределение Хне отличается от теоретического (ожидаемого). Метод: критерий/2-Пирсона.
Анализ таблиц сопряженности
Следует различать три ситуации — в зависимости от числа градаций и соотношения Хи Y: О число градаций Хи (или) Y больше двух (общий случай); □ таблицы сопряженности 2x2 с независимыми выборками;Общий случай: число градаций больше двух
Исследовались различия между мужчинами и женщинами в предпочтениях пяти политических лидеров. ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ Структура исходных данных:Таблицы сопряженности 2x2 с независимыми выборками
Методом «потерянных писем» исследовалась склонность людей передавать хорошие и плохие новости. Из 60 открыток с «хорошими» новостями до адресата… К(открытки) не отправленные отправленные А'(новость) плохаяТаблицы сопряженности 2x2 с повторными измерениями
Необходимо сравнить два вопроса, заданных одной и той же группе испытуемых, по соотношению ответов «да» и «нет»: …Сравнение двух независимых выборок
ПРИМЕР_________________________________________________________________________ Исследование различий между юношами и девушками по тревожности, измеренной в… № ЛГ(пол) У(тревожность) …Сравнение 2-х зависимых выборок
ГЛАВА 8. ВЫБОР МЕТОДА СТАТИСТИЧЕСКОГО ВЫВОДА знак измерен дважды на одной и той же выборке, либо каждому испытуемому из… ПРИМЕРЫ______________________________________________________Сравнение более двух выборок
Проверяемая Но: несколько совокупностей (которым соответствуют выборки) не отличаются по уровню выраженности измеренного признака.
Сравнение более двух независимых выборок
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ ПРИМЕР Исследовалось влияние интервала между 5 повторениями вербального материала на продуктивность (Y) последующего его…АНАЛИЗ НОМИНАТИВНЫХ ДАННЫХ
ПРИМЕРЫ_____________________________________________________________ Кто чаще обращается в службу знакомств: мужчины или женщины? Зависит ли… Можно ли утверждать, что выигрыши в игре распределены не случайно среди проигрышей?СРАВНЕНИЕ ЭМПИРИЧЕСКОГО И ТЕОРЕТИЧЕСКОГО
РАСПРЕДЕЛЕНИЙ
Две градации
ПРИМЕР______________________________________________________ Мы можем сопоставлять долю мужчин, которым больше нравятся блондинки, с долей… Обычно, сопоставляя доли, мы надеемся обнаружить различия их пропорции от некоторого ожидаемого соотношения.…Обработка на компьютере: биномиальный критерий
Выбираем: Analyze (Метод) > Nonparametric tests... (Непараметрические методы) > Binomial... (Биномиальный). В открывшемся окне диалога… Если теоретическое распределение является равномерным, то нажимаем ОК и… Если теоретическое распределение не является равномерным, то необходимо задать ожидаемые (теоретические) пропорции…Binomial Test
a Alternative hypothesis states that the proportion of cases in the first group < .52. Observed Prop. — наблюдаемая доля для каждой категории (Category); Test Prop.… Примечание. Если проверяется ненаправленная гипотеза, то полученное значение/7-уровня необходимо умножить на 2.Test Statistics
a 0 cells (.0%) have expected frequencies less than 5. The minimum expected cell frequency is 24.0. Chi-square — значение %l Asymp. Sig. — /^-уровень значимости. ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗЧисло градаций больше двух
(9.2) Формула для расчета теоретической частоты для ячейки /-строки иу'-столбца: … (9.3)Независимые выборки
По сравнению с другими таблицами сопряженности особенность таблиц 2x2 проявляется в трех отношениях. 1. Эти таблицы могут быть построены разными способами, но только один из них является правильным в отношении применимости критерия % -Пирсона.Повторные измерения
ПРИМЕР 9,6___________________________________________________________ Исследовалось влияние убедительной лекции о введении моратория на смертную… В таблице исходных данных в таких случаях каждой строке (объекту выборки) соответствуют два значения (в двух столбцах…КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Коэффициент корреляции — это мера прямой или обратной пропорциональности между двумя переменными. Он чувствителен к связи только в том случае,… Основные показатели: сила, направление и надежность (достоверность) связи.… Условия применения коэффициентов корреляции:ПРИМЕР 10.1
 На выборке 7V= 20 (учащиеся 8-го класса) были измерены два показателя интеллекта: вербального (х) и невербального (у) (см. пример 6.1). Коэффициент корреляции составил: гху= 0,517. Проверим гипотезу о связи этих показателей двумя способами. Подставив величины Лг=20игх>,= 0,517вформулу 10.1, получаем: ?., = 2,562; df= 18. По таблице критических значений /-Стьюдента (приложение 2) для df= 18 видим, что эмпирическое значение находится между критическими значениями для р = 0,05и/? = 0,01.
На выборке 7V= 20 (учащиеся 8-го класса) были измерены два показателя интеллекта: вербального (х) и невербального (у) (см. пример 6.1). Коэффициент корреляции составил: гху= 0,517. Проверим гипотезу о связи этих показателей двумя способами. Подставив величины Лг=20игх>,= 0,517вформулу 10.1, получаем: ?., = 2,562; df= 18. По таблице критических значений /-Стьюдента (приложение 2) для df= 18 видим, что эмпирическое значение находится между критическими значениями для р = 0,05и/? = 0,01.
р> 0,1 р<0,1 р<0,05 р<0,01 р< 0,001

Следовательно, для нашего случая р < 0,05. Тот же результат мы получим, минуя вычисление /-Стьюдента, воспользовавшись таблицей критических значений коэффициента корреляции r-Пирсона (приложение 6): в строке, соответствующей N— 20, видим, что эмпирическое значение корреляции находится между критическими значениями для р = 0,05 и р = 0,01. Следовательно, р < 0,05. (При расчете на компьютере значение коэффициента корреляции будет сопровождаться точным значением р-уровня, для данного случая: р = 0,019.)
Статистическое решение: Но: гху = 0 отклоняется для а = 0,05. Содержательный вывод: обнаружена статистически достоверная положительная связь вербального и невербального интеллекта для учащихся 8-го класса (гху= 0,517, N= 20, р < 0,05).
Замечания к применению метрических коэффициентов корреляции.Если связь (статистически достоверная) не обнаружена, но есть основания полагать, что связь на самом деле есть, то следует проверить возможные причины недостоверности связи.

|
1. Нелинейность связи: просмотреть график двумерного рассеивания. Если
связь нелинейная, но монотонная, перейти кранговым корреляциям. Если связь
не монотонная, то делить выборку на части, в которых связь монотонная, и вычи
слить корреляции отдельно для каждой части выборки, или делить выборку на
контрастные группы и далее сравнивать их по уровню выраженности признака.
2. Наличие выбросов и выраженная асимметрия распределения одного или
обоих признаков. Просмотреть гистограммы рас
пределения частот того и другого признака. При
наличии выбросов или асимметрии исключить выбросы или перейти к ранговым корреляциям.
3. Неоднородность выборки: просмотреть график
двумерного рассеивания. Попытаться разделить
выборку на части, в которых связь может иметь раз
ные направления.
 Если связь не обнаружена, но есть основания полагать, что связь на самом деле есть...
Если связь не обнаружена, но есть основания полагать, что связь на самом деле есть...
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
Если связь статистически достоверна, то прежде, чем делать содержательный вывод, следует исключить возможность «ложной» корреляции.
1. Связь обусловлена выбросами: просмотреть график двумерного рассеи
вания. При наличии выбросов перейти к ранговым корреляциям или исклю
чить выбросы.
2. Связь обусловлена влиянием третьей переменной: просмотреть график
двумерного рассеивания на предмет наличия содержательно интерпретируе
мого деления выборки на группы, для которых согласованно меняются сред
ние двух переменных. Если подобное явление возможно, необходимо вычис
лить корреляцию не только для всей выборки, но и для каждой группы в
отдельности. Если «третья» переменная метрическая — вычислить частную
корреляцию.
ЧАСТНАЯ КОРРЕЛЯЦИЯ
Если изучается связь между тремя метрическими переменными, то возможна проверка предположения о том, что связь между двумя переменными Хи Y не зависит от влияния третьей переменной — Z. Для этого можно вычислить коэффициент частной корреляции rxy_z:
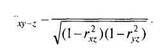
|
_ Гху ~rxzryz r
Напомним, что коэффициент гху_г тем больше по абсолютной величине (ближе к гху), чем меньше связь между А" и Г обусловлена влиянием Z. Коэффициент гху_, близок к 0, если связь между Хи /близка к 0 при любом фиксированном значении Z, то есть связь между Хи /обусловлена влиянием Z.
Основной (нулевой) статистической гипотезой является равенство частной корреляции нулю в генеральной совокупности (Но: rxy_z = 0). Определение /^-уровня значимости осуществляется при помощи критерия /-Стьюдента:

Если р < а, Но отклоняется и делается содержательный вывод о том, что обнаружена статистически достоверная связь х и у при фиксированных значениях z, то есть связь между хи у не зависит от влияния z- Когда/) >а, Но не отклоняется, и содержательный вывод ограничен констатацией того, что связь (статистически достоверная) между х и у при фиксированных значениях z не обнаружена.
ГЛАВА 10. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
ПРОВЕРКА ГИПОТЕЗ О РАЗЛИЧИИ КОРРЕЛЯЦИЙ
Задача сравнения корреляций имеет два варианта решения: а) для независимых выборок — когда необходимо сравнить два коэффициента корреляции, полученных на разных выборках между одними и теми же переменными; б) для зависимых выборок — когда необходимо сравнить корреляцию переменных X и Ус корреляцией переменных Хп Z, при условии, что все три переменные измерены на одной и той же выборке1.
Сравнение корреляций для независимых выборок
По результатам сравнения корреляций в данном случае можно делать вывод о различии корреляции признаков Хч Уъ двух сравниваемых совокупностях. Проверяемая Но содержит утверждение о равенстве корреляций в генеральной совокупности.
ПРИМЕР 10.2__________________________________________________________
В одном исследовании сравнивалась связь интеллекта и среднего балла отметок учащихся 6-х классов и учащихся 11-х классов. Для 50 учащихся 6-х классов корреляция составила г{ = 0,63 (р < 0,001), а для 60 учащихся 11-х классов — г2 — 0,31 (р < 0,05). Можно ли на основании этих данных утверждать, что в 11-х классах связь отметок с интеллектом слабее, чем в 6-х классах?
Задача статистической проверки подобных предположений решается при помощи Z-преобразования Фишера коэффициентов корреляции и последующего применения Z-критерия. Z-преобразование Фишера — это пересчет коэффициентов корреляции г по формуле:

|
Z = W~- (Ю.З)
2 -г
| Для облегчения пересчета можно воспользоваться функцией «ФИШЕР» в программе Excel либо таблицей, составленной с ее помощью (приложение 7). Эмпирическое значение Z-критерия для определения /?-уровня значимое- |
Для облегчения пересчета можно воспользоваться функцией «ФИШЕР» в программе Excel либо таблицей, составленной с ее помощью (приложение 7).
Эмпирическое значение Z-критерия для определения /?-уровня значимости различия корреляций вычисляется по формуле:

|
Z = , Z'"Z;_, (10.4)
1 Методы этого раздела заимствованы из: Гласе Дж., Стенли Дж. Статистические методы is педагогике и психологии. М., 1977. С. 283—286.
 151
151
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
где Zx и Z2 — Z-преобразованные значения сравниваемых корреляций, Nx и N2 — соответствующие объемы выборок. Уровень значимости определяется по формуле р < 2Р, где Р — площадь справа от Z, под кривой нормального распределения.
ПРИМЕР 10.2(продолжение)
 Проверим гипотезу о различии коэффициентов корреляции (а = 0,05).
Проверим гипотезу о различии коэффициентов корреляции (а = 0,05).
Ш а г 1. Производим Z-преобразование Фишера в отношении сравниваемых корреляций, воспользовавшись таблицей из приложения 7:

|
Z, = 0,741; Z2 = 0,321. Ш а г 2. Вычислим эмпирическое значение Z-критерия по формуле 10.4:
Z = ,0'74'-°'321 =2,136-
50-3 60-3
Шаг 3. Определим ^-уровень значимости. По таблице стандартных нормальных вероятностей (приложение 1) определяем площадь справа от табличного z, ближайшего меньшего Zr Справа от<:= 2,13: Р= 0,0166. Уровень значимости определяется по формуле р<2Р. Следовательно, р < 0,033.
Ш а г 4. Принимаем статистическое решение и формулируем содержательный вывод. Статистическое решение: отклоняем Но (о равенстве корреляций в генеральной совокупности). Содержательный вывод: в 11-х классах связь отметок с интеллектом статистически значимо ниже, чем в 6-х классах (р < 0,033).
Отметим, что одна и та же разность между корреляциями будет иметь более высокую статистическую значимость при больших значениях корреляции и меньшую — при более слабых корреляциях. Так, уменьшение значений корреляций всего на 0,1 в примере 10.2 привело бы кр > 0,05.
Сравнение корреляций для зависимых выборок
В данном случае предполагается сравнение корреляции Хи Yc корреляцией Л1 и Znpn условии, что все три признака измерены на одной и той же выборке. Проверяемая Но содержит утверждение о равенстве соответствующих корреляций.
ПРИМЕР 10.3_____________________________________________________________________
Сравнивалась прогностическая эффективность двух шкал вступительного теста в отношении предсказания среднего балла отметок студентов 2 курса. На выборке в 95 студентов корреляция результатов тестирования и среднего балла отметок составила: для первой шкалы: /-, = 0,60; для второй шкалы: г2 = 0,46; корреляция результатов двух тестов: гп = 0,70. Можно ли утверждать, что прогностическая цен-
ность первой шкалы достоверно выше, чем второй?
ГЛАВА 10. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Для статистической проверки подобных гипотез применяется Z-критерий, эмпирическое значение которого вычисляется по формуле:
 |

|
. - rlУ + (1 - гД )2 - 2^ - (2^ - /ухг)(1 - г2ху - ^ - 4>
ПРИМЕР 10.3 (продолжение)
 Проверим гипотезу о различии коэффициентов корреляции (а = 0,05).
Проверим гипотезу о различии коэффициентов корреляции (а = 0,05).
Ш а г 1. Вычислим эмпирическое значение Z-критерия по формуле 10.5: Z, = 2,l 19.
Ш а г 2. Определим /^-уровень значимости. По таблице стандартных нормальных вероятностей (приложение 1) определяем площадь справа от табличного z, ближайшего меньшегоZ,. Справаотг= 2,11: /*= 0,0174. Уровень значимости определяется по формуле р<2Р. Следовательно, р < 0,035.
Ш а г 3. Принимаем статистическое решение и формулируем содержательный вывод. Статистическое решение: отклоняем Но (о равенстве корреляций в генеральной совокупности). Содержательный вывод: корреляция второй шкалы теста статистически достоверно ниже корреляции первой шкалы со средним баллом отметок студентов 2-го курса (р < 0,05) — прогностическая ценность первой шкалы выше, чем второй шкалы.
Отметим, что для решения такой задачи можно было бы рассматривать выборки как независимые и применять соответствующий метод сравнения корреляций — по формулам 10.3 и 10.4. Но чувствительность (мощность) такой проверки была бы гораздо ниже. В частности, применяя кданным примера 10.3 предыдущий метод, мы получим/? = 0,18, что приводит к принятию Но.
КОРРЕЛЯЦИЯ РАНГОВЫХ ПЕРЕМЕННЫХ
Если к количественным данным неприменим коэффициент корреляции г-Пирсона, то для проверки гипотезы о связи двух переменных после предварительного ранжирования могут быть применены корреляции r-Спирмеиа или т-Кендалла.
r-Спирмена. Этот коэффициент корреляции вычисляется либо путем применения формулы /"-Пирсона к предварительно ранжированным двум переменным, либо, при отсутствии повторяющихся рангов, по упрощенной формуле:
 7V(7V2 -1)
7V(7V2 -1)
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
Поскольку этот коэффициент — аналог /--Пирсона, то и применение /•-Спирмена для проверки гипотез аналогично применению /--Пирсона, изложенному ранее1.
Преимущество r-Спирмена по сравнению с /--Пирсона — в большей чувствительности к связи в случае:
□ существенного отклонения распределения хотя бы одной переменной
от нормального вида (асимметрия, выбросы);
□ криволинейной (монотонной) связи.
Недостаток r-Спирмена по сравнению с /--Пирсона — в меньшей чувствительности к связи в случае несущественного отклонения распределения обеих переменных от нормального вида.
Частная корреляция и сравнение корреляций применимы и к г-Спирмена.

|
т-Кендалла. Применяется к предварительно ранжированным данным как альтернатива /--Спирмена. т-Кендалла, как отмечалось в главе 6, имеет более выгодную, вероятностную интерпретацию. Общая формула для вычисления r-Кендалла, вне зависимости от наличия или отсутствия повторяющихся рангов (связей):
______________ P^Q____________
J[N(N-)/2]-Kj[N(N-)/2]-Ky '
| где Р — число совпадений, Q — число инверсий, Кх и Ку — поправки на связи в рангах (см. главу 6: Проблема связанных (одинаковых) рангов). Если связей в рангах нет, то знаменатель формулы равен Р+ Q= N(N~)/2. Поскольку природа г-Кендалла иная, чем у r-Спирмена и /--Пирсона, то /^-уровень определяется по-другому: применяется г-критерий и единичное нормальное распределение. Эмпирическое значение вычисляется по формуле: |
где Р — число совпадений, Q — число инверсий, Кх и Ку — поправки на связи в рангах (см. главу 6: Проблема связанных (одинаковых) рангов). Если связей в рангах нет, то знаменатель формулы равен Р+ Q= N(N~)/2.

|
| (.0.6, |
Поскольку природа г-Кендалла иная, чем у г-Спирмена и /--Пирсона, то /^-уровень определяется по-другому: применяется г-критерий и единичное нормальное распределение. Эмпирическое значение вычисляется по формуле:
При вычислениях «вручную» /^-уровень определяется по следующему алгоритму:
а) вычисляется эмпирическое значение гэ;
б) по таблице «Стандартные нормальные вероятности» (приложение 1)
определяется теоретическое значение х, ближайшее меньшее к эмпири
ческому значению z3',
в) определяется площадь Рпод, кривой справа от гт;
г) вычисляется ^-уровень по формуле/? < 2Р.
Проверяемая статистическая гипотеза, порядок принятия статистического решения и формулировка содержательного вывода те же, что и для случая г-Пирсона или г-Спирмена.
 1 В некоторых источниках по непонятным причинам для /--Пирсона и r-Спирмена приводят разные таблицы критических значений. В компьютерных программах (SPSS, STATISTICA) уровни значимости для одинаковых /--Пирсона и r-Спирмена всегда совпадают.
1 В некоторых источниках по непонятным причинам для /--Пирсона и r-Спирмена приводят разные таблицы критических значений. В компьютерных программах (SPSS, STATISTICA) уровни значимости для одинаковых /--Пирсона и r-Спирмена всегда совпадают.
При вычислениях на компьютере статистическая программа (SPSS, Statistica) сопровождает вычисленный коэффициент корреляции более точным значением /ьуровня.
ПРИМЕР 10.4_____________________________________________________________________
Предположим, для каждого из 12 учащихся одного класса известно время решения тестовой арифметической задачи в секундах (X) и средний балл отметок по математике за последнюю четверть (Y). При подсчете т-Кендалла были получены следующие результаты: Р= 18; Q= 48; т = —0,455. Проверим гипотезу о связи времени решения тестовой задачи и среднего балла отметок по математике.
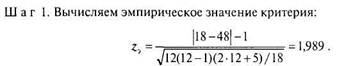
Ш а г 2. По таблице «Стандартные нормальные вероятности» (приложение 1) находим ближайшее меньшее, чем z3, теоретическое значение zT и площадь справа от этого z,: zT - 1,98; площадь справа Р = 0,024.
Ш а г 3. Вычисляемр-уровень по формуле/) < 2Р;р < 0,048.
Ш а г 4. Принимаем статистическое решение. Нулевая гипотеза об отсутствии связи в генеральной совокупности отклоняется на уровне а = 0,05.
Ш а г 5. Формулируем содержательный вывод. Обнаружена отрицательная связь между временем решения тестовой арифметической задачи и средним баллом отметок по математике за последнюю четверть (х = -0,455; N= 2;p< 0,048). Величина корреляции показывает, что при сравнении испытуемых друг с другом более высокий средний балл будет сочетаться с меньшим временем решения задач чаще, чем в 70% случаях, так как вероятность инверсий P{q) = (1 — т)/2 = = (1+0,455)/2 = 0,728.
(Отметим, что при вычислении т-Кендалла по этим данным на компьютере были получены следующие результаты: т = -0,455; р = 0,040.)
Сравнениеr-Спирменаих-Кендалла. Интерпретация r-Спирмена аналогична интерпретации r-Пирсона. Квадрат и того, и другого коэффициента корреляции (коэффициент детерминации) показывает долю дисперсии одной переменной, которая может быть объяснена влиянием другой переменной. х-Кен-далла имеет другую интерпретацию: это разность вероятностей совпадений и инверсий в рангах. Кроме того, по величине х-Кендалла можно судить о вероятности совпадений Р{р) = (1 + т)/2 или инверсий P{q) = (1 — х)/2.
Для одних и тех оке данных величина r-Спирмена всегда больше, чем х-Кендалла, исключая крайние значения 0 и 1. Это отражает тот факт, что х-Кендалла зависит от силы связи линейно, а r-Спирмена — не линейно. В то же время для одних и тех же данных р-уровень i-Кендалла и r-Спирмена примерно одинаков, а иногда х-Кендалла имеет преимущество в уровне значимости.
Замечания к применению.Если связь (статистически достоверная) не обнаружена, но есть основания полагать, что связь на самом деле есть, то следует
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
сначала перейти от г-Спирмена к т-Кендалла (или наоборот), а затем проверить другие возможные причины недостоверности связи.
1. Нелинейность связи: просмотреть график двумерного рассеивания. Если
связь не монотонная, то делить выборку на части, в которых связь мо
нотонная, или делить выборку на контрастные группы и далее сравни
вать их по уровню выраженности признака.
2. Неоднородность выборки: просмотреть график двумерного рассеивания.
Попытаться разделить выборку на части, в которых связь может иметь
разные направления.
Если связь статистически достоверна, то прежде, чем делать содержательный вывод, следует исключить возможность наличия «ложной» корреляции, как следствия влияния третьей переменной (см. Замечания к применению метрических коэффициентов корреляции).
АНАЛИЗ КОРРЕЛЯЦИОННЫХ МАТРИЦ
Корреляционная матрица.Часто корреляционный анализ включает в себя изучение связей не двух, а множества переменных, измеренных в количественной шкале на одной выборке. В этом случае вычисляются корреляции для каждой пары из этого множества переменных. Вычисления обычно проводятся на компьютере, а результатом является корреляционная матрица.
Корреляционная матрица(Correlation Matrix) — это результат вычисления корреляций одного типа для каждой пары из множества Р переменных, измеренных в количественной шкале на одной выборке.
ПРИМЕР______________________________________________________________
Предположим, изучаются связи между 5 переменными (vl, v2,..., v5; P= 5), измеренными на выборке численностью N=30 человек. Ниже приведена таблица исходных данных и корреляционная матрица.
Исходные данные:
Корреляционная матрица:

|

|
Нетрудно заметить, что корреляционная матрица является квадратной, симметричной относительно главной диагонали (таккакг,у= /}у), с единицами на главной диагонали (так как ги = Гу = 1).
ГЛАВА 10. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Корреляционная матрица является квадратной: число строк и столбцов равно числу переменных. Она симметрична относительно главной диагонали, так как корреляция х с у равна корреляции у с х. На ее главной диагонали располагаются единицы, так как корреляция признака с самим собой равна единице. Следовательно, анализу подлежат не все элементы корреляционной матрицы, а те, которые находятся выше или ниже главной диагонали.
Количество коэффициентов корреляции, подлежащих анализу при изучении связей Рпризнаков определяется формулой: Р(Р- 1)/2. В приведенном выше примере количество таких коэффициентов корреляции 5(5 — 1)/2 = 10.
Основная задача анализа корреляционной матрицы — выявление структуры взаимосвязей множества признаков. При этом возможен визуальный анализ корреляционных плеяд — графического изображения структуры статистически значимых связей, если таких связей не очень много (до 10—15). Другой способ — применение многомерных методов: множественного регрессионного, факторного или кластерного анализа (см. раздел «Многомерные методы...»). Применяя факторный или кластерный анализ, можно выделить группировки переменных, которые теснее связаны друг с другом, чем с другими переменными. Весьма эффективно и сочетание этих методов, например, если признаков много и они не однородны.
Сравнение корреляций — дополнительная задача анализа корреляционной матрицы, имеющая два варианта. Если необходимо сравнение корреляций в одной из строк корреляционной матрицы (для одной из переменных), применяется метод сравнения для зависимых выборок (с. 148—149). При сравнении одноименных корреляций, вычисленных для разных выборок, применяется метод сравнения для независимых выборок (с. 147-148).
Методы сравнения корреляций в диагоналях корреляционной матрицы (для оценки стационарности случайного процесса) и сравнения нескольких корреляционных матриц, полученных для разных выборок (на предмет их однородности), являются трудоемкими и выходят за рамки данной книги. Познакомиться с этими методами можно по книге Г. В. Суходольского1.
Проблема статистической значимости корреляций.Проблема заключается в том, что процедура статистической проверки гипотезы предполагает однократное испытание, проведенное на одной выборке. Если один и тот же метод применяется многократно, пусть даже и в отношении различных переменных, то увеличивается вероятность получить результат чисто случайно. В общем случае, если мы повторяем один и тот же метод проверки гипотезы к раз в отношении разных переменных или выборок, то при установленной величине а мы гарантированно получим подтверждение гипотезы в ахк числе случаев.
Предположим, анализируется корреляционная матрица для 15 переменных, то есть вычислено 15(15—1)/2 = 105 коэффициентов корреляции. Для проверки гипотез установлен уровень а = 0, 05. Проверяя гипотезу 105 раз, мы пять раз (!) получим ее подтверждение независимо от того, существует ли связь на самом деле. Зная это и
 Суходольский Г. В. Основы математической статистики для психологов. СПб., 1998. С. 299-302.
Суходольский Г. В. Основы математической статистики для психологов. СПб., 1998. С. 299-302.
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
получив, скажем, 15 «статистически достоверных» коэффициентов корреляции, сможем ли мы сказать, какие из них получены случайно, а какие — отражают реальную связь?
Строго говоря, для принятия статистического решения необходимо уменьшить уровень а во столько раз, сколько гипотез проверяется. Но вряд ли это целесообразно, так как непредсказуемым образом увеличивается вероятность проигнорировать реально существующую связь (допустить ошибку II рода).
Одна только корреляционная матрица не является достаточным основанием для статистических выводов относительно входящих в нее отдельных коэффициентов корреляций!
Можно указать лишь один действительно убедительный способ решения этой проблемы: разделить выборку случайным образом на две части и принимать во внимание только те корреляции, которые статистически значимы в обеих частях выборки. Альтернативой может являться использование многомерных методов (факторного, кластерного или множественного регрессионного анализа) — для выделения и последующей интерпретации групп статистически значимо связанных переменных.
Проблема пропущенных значений.Если в данных есть пропущенные значения, то возможны два варианта расчета корреляционной матрицы: а) построчное удаление значений (Exclude cases listwise);б) попарное удаление значений (Exclude cases pairwise).При построчном удалении наблюдений с пропусками удаляется вся строка для объекта (испытуемого), который имеет хотя бы одно пропущенное значение по одной из переменных. Этот способ приводит к «правильной» корреляционной матрице в том смысле, что все коэффициенты вычислены по одному и тому же множеству объектов. Однако если пропущенные значения распределены случайным образом в переменных, то данный метод может привести к тому, что в рассматриваемом множестве данных не останется ни одного объекта (в каждой строке встретится, по крайней мере, одно пропущенное значение). Чтобы избежать подобной ситуации, используют другой способ, называемый попарным удалением. В этом способе учитываются только пропуски в каждой выбранной паре столбцов-переменных и игнорируются пропуски в других переменных. Корреляция для пары переменных вычисляется по тем объектам, где нет пропусков. Во многих ситуациях, особенно когда число пропусков относительно мало, скажем 10%, и пропуски распределены достаточно хаотично, этот метод не приводит к серьезным ошибкам. Однако иногда это не так. Например, в систематическом смещении (сдвиге) оценки может «скрываться» систематическое расположение пропусков, являющееся причиной различия коэффициентов корреляции, построенных по разным подмножествам (например — для разных подгрупп объектов). Другая проблема, связанная с корреляционной матрицей, вычисленной при попарном удалении пропусков, возникает при использовании этой матрицы в других видах анализа (например, в множественном регрессионном или факторном анализе). В них предполагается, что используется «правильная» корреляционная матрица с определенным уровнем состоятельности и «соответствия» различных коэффициентов. Использование матрицы с «плохими» (смещенными) оценками при-
ГЛАВА 10. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
водит к тому, что программа либо не в состоянии анализировать такую матрицу, либо результаты будут ошибочными. Поэтому, если применяется попарный метод исключения пропущенных данных, необходимо проверить, имеются или нет систематические закономерности в распределении пропусков.
Если попарное исключение пропущенных данных не приводит к какому-либо систематическому сдвигу средних значений и дисперсий (стандартных отклонений), то эти статистики будут похожи на аналогичные показатели, вычисленные при построчном способе удаления пропусков. Если наблюдается значительное различие, то есть основание предполагать наличие сдвига в оценках. Например, если среднее (или стандартное отклонение) значений переменной А, которое использовалось при вычислении ее корреляции с переменной В, намного меньше среднего (или стандартного отклонения) тех же значений переменной А, которые использовались при вычислении ее корреляции с переменной С, то имеются все основания ожидать, что эти две корреляции (А—В нА—С) основаны на разных подмножествах данных. В корреляциях будет сдвиг, вызванный неслучайным расположением пропусков в значениях переменных.
Анализ корреляционных плеяд.После решения проблемы статистической значимости элементов корреляционной матрицы статистически значимые корреляции можно представить графически в виде корреляционной плеяды или плеяд. Корреляционная плеяда — это фигура, состоящая из вершин и соединяющих их линий. Вершины соответствуют признакам и обозначаются обычно цифрами — номерами переменных. Линии соответствуют статистически достоверным связям и графически выражают знак, а иногда — и /j-уровень значимости связи.
 Корреляционная плеяда может отражать все статистически значимые связи корреляционной матрицы (иногда называется корреляционным графом) или только их содержательно выделенную часть (например, соответствующую одному фактору по результатам факторного анализа).
Корреляционная плеяда может отражать все статистически значимые связи корреляционной матрицы (иногда называется корреляционным графом) или только их содержательно выделенную часть (например, соответствующую одному фактору по результатам факторного анализа).
 Корреляционный граф и его родственные связи, достоверность которых была установлена в судебном порядке
Корреляционный граф и его родственные связи, достоверность которых была установлена в судебном порядке
ПРИМЕР ПОСТРОЕНИЯ КОРРЕЛЯЦИОННОЙ ПЛЕЯДЫ

ЧАСТЬ П. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
Корреляционная плеяда:

|

|
Построение корреляционной плеяды начинают с выделения в корреляционной матрице статистически значимых корреляций (иногда — разным цветом в зависимости от/?-уровня значимости). Затем для строк (столбцов) матрицы, содержащих статистически значимые корреляции, подсчитывается их количество. Построение плеяды начинают с переменной, имеющей наибольшее число значимых связей, постепенно добавляя в рисунок другие переменные — по мере убывания числа связей и связывая их линиями, соответствующими связям между ними.
ОБРАБОТКА НА КОМПЬЮТЕРЕ
Графики двумерного рассеивания.Выбираем Graphs... > Scatter...-Simple.Нажимаем Define.В появляющемся окне назначаем осям переменные: выделяем слева одну переменную, нажимаем > напротив «X Axis» (ОсьХ), выделяем другую переменную, нажимаем > напротив «Y Axis». Нажимаем ОК. Получаем график рассеивания назначенных переменных.
Вычисление симметричной корреляционной матрицы.(По умолчанию SPSS вычисляет полную корреляционную матрицу.)
Выбираем Analyze> Correlate > Bivariate... Воткрывшемся окне диалога выделяем интересующие переменные в левой части и переносим их в правую часть при помощи кнопки > (переменных должно быть как минимум две).
По умолчанию стоит флажок Pearson(корреляция /--Пирсона). Если интересует корреляция r-Спирмена или х-Кендалла, необходимо поставить соответствующие флажки внизу.
Если в данных есть пропуски, то по умолчанию программа учтет их путем попарного удаления (exclude cases pairwise).Если необходимо учесть их путем построчного удаления (объектов с пропусками), то нажимаем Options... > (Exclude cases listwise) > Continue...
Нажимаем ОК. В появившейся таблице строки и столбцы соответствуют выделенным ранее переменным. В ячейке на пересечении строки и столбца, соответствующих интересующим нас переменным, видим три числа: верхнее
ГЛАВА 10. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
соответствует коэффициенту корреляции, нижнее — численности выборки N, среднее — /^-уровню значимости для ненаправленных альтернатив (Sig. (2-tailed)).
Вычисление несимметричной корреляционной матрицы.Если есть необходимость вычислить корреляции не всех, а только двух групп переменных, то необходимо создание командного файла (Syntax). Например, есть 5 переменных с именами: vl, v2, v3, v4, v5. Задача — вычислить корреляции vl с остальными переменными из этого набора, обрабатывая пропуски путем попарного удаления.
□ Выбираем File> New > Syntax. Воткрывшемся окне набираем текст:
correlations variables vl with v2 v3 v4 v5.
(Количество переменных до и после слова with — не ограничено).
П Если необходима обработка пропусков путем построчного удаления, то: correlations variables vl with v2 v3 v4 v5 /missing listwise.
П Если надо вычислить корреляцию r-Спирмена (с попарным удалением), то: nonpar corr vl with v2 v3 v4 v5.
□ Для вычисления корреляций т-Кендалла добавляем к первой — вторую
строку:
nonpar corr vl with v2 v3 v4 v5 /print kendall.
□ Для вычисления и r-Спирмена, и т-Кендалла с построчным удалением:
nonpar corr vl with v2 v3 v4 v5
/missing listwise /print both.
Заметьте, что вся команда обязательно должна заканчиваться точкой.
Для выполнения команды нажимаем Run> АН. Программа выдаст результат — таблицу корреляций переменных. Строки будут соответствовать именам переменных, указанных в команде до слова with, а столбцы — именам переменных, указанных после слова with.
Вычисление частной корреляции.Выбираем Analyze> Correlate > Partial...В открывшемся окне диалога переносим интересующие переменные из левой части в правую верхнюю (Variables:) при помощи верхней кнопки > (переменных должно быть как минимум две). Затем при помощи нижней кнопки > из правой части в левую нижнюю часть (Controlling for:)переносим переменную, значения которой хотим фиксировать. Нажимаем ОК. Получаем таблицу, аналогичную таблице парных корреляций, но верхнее число в каждой ячейке — значение частной корреляции соответствующих двух переменных при фиксированном значении указанной третьей переменной. Нижнее число — /^-уровень значимости, а посередине — число степеней свободы.
Глава 11
ПАРАМЕТРИЧЕСКИЕ МЕТОДЫ СРАВНЕНИЯ ДВУХ ВЫБОРОК
К параметрическим методам относится и сравнение дисперсий двух выборок по критерию F-Фишера. Иногда этот метод приводит к ценным содержательным… При сравнении средних или дисперсии двух выборок проверяется ненаправленная… СРАВНЕНИЕ ДИСПЕРСИЙКРИТЕРИЙ Г-СТЬЮДЕНТА ДЛЯ ЗАВИСИМЫХ ВЫБОРОК
Проверяемая статистическая гипотеза, как и в предыдущем случае, Н(): М] = М2. При ее отклонении принимается альтернативная гипотеза о том, что М{… Исходные предположения для статистической проверки: П каждому представителю одной выборки (из одной генеральной совокупности) поставлен в соответствие представитель…ОБРАБОТКА НА КОМПЬЮТЕРЕ
Критерий r-Стьюдента для одной выборки.
Б) Воткрывшемся окне диалога выделяем и переносим интересующие переменные из левого окна в правое окно при помощи кнопки > (в данном случае —… B) Получаем результаты в виде двух таблиц: …One-Sample Statistics
В первой таблице содержатся первичные статистики, в частности, средние значения (Means), стандартные отклонения (Std. Deviation). Во второй — результаты проверки гипотез: значения /-Стьюдента (/), числа степеней свободы (df), уровень значимости (Sig.), разность среднего значения и заданной величины (Mean Difference).
Критерий Г-Стьюдента и сравнение двух дисперсий для независимых выборок.
A)Выбираем Analyze > Compare means > Independent Samples T-Test...
Б) В открывшемся окне диалога выделяем и переносим при помощи кнопки > из левого окна интересующие переменные в правое верхнее окно (Test Variable(s))(в данном случае — переменную varl); группирующую переменную, которая делит выборку на подгруппы (Grouping Variable)(в данном случае — переменную var2). Нажимаем кнопку Define Groups...и задаем номера градаций группирующей переменной, которые мы хотим сравнить (в данном случае 0 и 1). Нажимаем Continue.Нажимаем ОК.
B)Получаем результаты в виде двух таблиц.
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
Group Statistics
t-test for Equality of Means VAR1 Equal variances assumedКритерий Г-Стьюдента для зависимых выборок.
A) Выбираем Analyze> Compare means > Paired-Samples T-Test.,.
Б) В открывшемся окне диалога выделяем две переменные (соответствующие двум зависимым выборкам — измерениям одного и того же признака) и переносим пару при помощи кнопки > из левого окна в правое окно (Paired Variables).Пар может быть несколько (в данном случае — это пара переменных var2 и var3). Нажимаем ОК.
B) Получаем результаты в виде трех таблиц:
Paired Samples Statistics
ГЛАВА It. ПАРАМЕТРИЧЕСКИЕ МЕТОДЫ СРАВНЕНИЯ ДВУХ ВЫБОРОКPaired Samples Test
Первая таблица содержит первичные статистики: каждой выборке соответствует своя строка. Во второй таблице — корреляция Пирсона для пары переменных,…Глава 12
НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ СРАВНЕНИЯ ВЫБОРОК
ОБЩИЕ ЗАМЕЧАНИЯ
Непараметрические методы заметно проще в вычислительном отношении, чем их параметрические аналоги. До недавнего прошлого простота вычислений имела… Непараметрические аналоги параметрических методов сравнения выборок… При решении вопроса о выборе параметрического или непараметрического метода сравнения необходимо иметь в виду, что…СРАВНЕНИЕ ДВУХ НЕЗАВИСИМЫХ ВЫБОРОК
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ рий серий (см. главу 8), который еще проще в вычислительном отношении, но… Эмпирическое значение критерия tZ-Манна-Уитни показывает, насколько совпадают (пересекаются) два ряда значений…Обработка на компьютере: критерий (7-Манна-Уитни
А) Выбираем Analyze> Nonparametric Tests > 2-Independent Samples...(Две независимые выборки). ЧАСТЬ Л. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ Б) В открывшемся окне диалога выделяем и переносим при помощи кнопки > из левого окна интересующие переменные (в…СРАВНЕНИЕ ДВУХ ЗАВИСИМЫХ ВЫБОРОК
ГЛАВА 12. НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ СРАВНЕНИЯ ВЫБОРОК Т^-Вилкоксона основан на ранжировании абсолютных разностей пар значений… Для расчетов «вручную» не требуется особых формул: достаточно подсчитать суммы рангов для положительных и…Обработка на компьютере: критерий Г-Вилкоксона
А) Выбираем Analyze> Nonparametric Tests > 2-Related Samples...(Две зависимые выборки). Б) В открывшемся окне диалога выделяем две переменные (соответствующие двум… ГЛАВА 12. НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ СРАВНЕНИЯ ВЫБОРОКRanks
a Based on negative ranks, b Wilcoxon Signed Ranks Test
В первой таблице содержатся ранговые статистики: средние ранги (Mean Rank)и суммы рангов (Sum of Ranks)для отрицательных (Negative Ranks)и положительных (Positive Ranks)сдвигов, а также количество одинаковых рангов (Ties). Во второй таблице содержатся результаты проверки гипотезы: эмпирическое значение ^-критерия (Z) и /^-уровень значимости (Asymp. Sig. (2-tailed)).
СРАВНЕНИЕ БОЛЕЕ ДВУХ НЕЗАВИСИМЫХ ВЫБОРОК
Я-Краскала-Уоллеса по идее сходен с критерием £/-Манна-Уитни. Как и последний, он оценивает степень пересечения (совпадения) нескольких рядов… ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ каждой из выборок. Если выполняется статистическая гипотеза об отсутствии различий, то можно ожидать, что все средние…#2
(12.2)
где N— суммарная численность всех выборок; к — количество сравниваемых выборок; Rj — сумма рангов для выборки /; п{ — численность выборки /. Чем сильнее различаются выборки, тем больше вычисленное значение Я и тем меньше/7-уровень значимости.
При расчетах «вручную» для определения /ьуровня пользуются таблицами критических значений. Если объем каждой выборки больше 5 и количество выборок больше трех, то эмпирическое значение критерия сравнивается с х2 (приложение 4) для df= k— (к — число выборок). Если сравниваются 3 выборки и объем каждой выборки меньше 5, то пользуются таблицей критических значений Я-Краскала-Уоллеса (приложение 12).
При отклонении нулевой статистической гипотезы об отсутствии различий принимается альтернативная гипотеза о статистически достоверных различиях выборок по изучаемому признаку — без конкретизации направления различий. Для утверждений о том, что уровень выраженности признака в какой-то из сравниваемых выборок выше или ниже, необходимо парное соотнесение выборок по критерию U-Манна-Уитни.
ПРИМЕР 12.3__________________________________________________________
Проверим гипотезу о различии выборок 1, 2 и 3 на уровне а = 0,05:

Шаг 1. Значения выборок объединяются в один ряд, упорядоченный в порядке возрастания или убывания. Обозначается принадлежность каждого значения к той или иной выборке (строки 1 и 2).
Ш а г 2. Значения выборок ранжируются и выписываются отдельно ранги для каждой выборки (строки 3-6).
Ш а г 3. Вычисляются суммы рангов для каждой выборки и проверяется правильность расчетов. R} = 46; R2 =49; R^ = 41. Общая сумма рангов должна быть равна N(N+ l)/2 = 16x17/2 = 136. Равенство соблюдено.
Ш а г 4. Вычисляется Я по формуле 12.2:
ГЛАВА 12. НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ СРАВНЕНИЯ ВЫБОРОК

Шаг 5. Определяется /?-уровень значимости. Хотя сравниваются 3 выборки, но объем одной из них больше 5, поэтому вычисленное Я сравнивается с табличным значением х2 (приложение 4) для числа степеней свободы df— 3 — 1—2. Эмпирическое значение Я находится между критическими для р = 0,05 и р = 0,01. Следовательно, р < 0,05.
Ш а г 6. Принимается статистическое решение и формулируется содержательный вывод. На уровне а = 0,05 гипотеза Но отклоняется. Содержательный вывод: сравниваемые выборки различаются статистически достоверно по уровню выраженности признака (р < 0,05).
Отметим, что на основании такой проверки мы не можем сделать конкретный вывод о направлении различий и о том, в какой выборке признак принимает большие или меньшие значения. Для этого необходимо парное соотнесение выборок по соответствующему критерию (£/-Манна-Уитни).
Обработка на компьютере: критерий Я-Краскала-Уоллеса
A) Выбираем Analyze> Nonparametric Tests > K-Independent Samples...(для ^-независимых выборок). Б) В открывшемся окне диалога выделяем и переносим при помощи кнопки > из… B) Получаем результаты в виде двух таблиц:СРАВНЕНИЕ БОЛЕЕ ДВУХ ЗАВИСИМЫХ ВЫБОРОК
Критерий х2-Фридмана основан на ранжировании ряда повторных измерений для каждого объекта выборки. Затем вычисляется сумма рангов для каждого из… Эмпирическое значение х2-Фридмана вычисляется после ранжирования ряда…Обработка на компьютере: критерий х2-Фридмана
A) Выбираем Analyze> Nonparametric Tests > К-Related Samples...(для /с-зависимых выборок). Б) В открывшемся окне диалога выделяем переменные (соответствующие нескольким… B) Получаем результаты в виде двух таблиц:Ranks
| Mean | Rank | ||
| VAR1 | 2. | ||
| VAR2 | 2. | ||
| VAR3 | 1. | ||
| VAR4 | 3 . | ||
| Test Statistics(a) | |||
| N | |||
| Chi-Square | 8.897 | ||
| df | |||
| Asymp. Sig. | .031 |
a Friedman Test
В первой таблице содержатся ранговые статистики: средние ранги для каждой группы (Mean Rank).Во второй таблице содержатся результаты проверки гипотезы: эмпирическое значение критерия %2 (Chi-Square),число степеней свободы (df) и/7-уровень значимости (Asymp. Sig.).
Глава 13
ДИСПЕРСИОННЫЙ АНАЛИЗ (ANOVA)
НАЗНАЧЕНИЕ И ОБЩИЕ ПОНЯТИЯ ANOVA1
Общепринятое сокращенное обозначение дисперсионного анализа — ANOVA (от англоязычного ANalysis Of VAriance). В соответствии с принятой классификацией, ANOVA — это метод сравнения нескольких (более двух) выборок по признаку, измеренному в метрической шкале. Как и в случае сравнения двух выборок при помощи критерия /-Стьюдента, ANOVA решает задачу сравнения средних значений, но не двух, а нескольких. Кроме того, метод допускает сравнение выборок более чем по одному основанию — когда деление на выборки производится по нескольким номинативным переменным, каждая из которых имеет 2 и более градаций.
ПРИМЕР______________________________________________________
Исследовалось влияние на продуктивность воспроизведения вербального материала (Y): а) интервала между 5 повторениями (Хх — 3 градации: 1 — 0 мин, 2 — 3 мин, 3 — 10 мин) и б) трудность материала (Х2 — 2 градации: 1 — легкий, 2 — трудный).
Структура данных:
| №.. | Л", (интервал) | Хг (объем) | /(эффективность воспроизведения) |
| N |
 1 В данной главе содержатся лишь самые необходимые сведения о дисперсионном анализе. Более полное изложение особенностей применения этого мощного и многогранного метода читатель может найти в других источниках, например, в кн.: Гусева А. Н. Дисперсионный анализ в экспериментальной психологии. М,, 2000.
1 В данной главе содержатся лишь самые необходимые сведения о дисперсионном анализе. Более полное изложение особенностей применения этого мощного и многогранного метода читатель может найти в других источниках, например, в кн.: Гусева А. Н. Дисперсионный анализ в экспериментальной психологии. М,, 2000.
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
Специфика ANOVA проявляется в двух отношениях: во-первых, этот метод использует терминологию планирования эксперимента; во-вторых, для сравнения средних значений анализируются компоненты дисперсии изучаемого признака.
ANOVA был разработан Р. Фишером специально для анализа результатов экспериментальных исследований. Соответственно, различные варианты ANOVA воспроизводят наиболее типичные планы организации эксперимента.
Типичная схема эксперимента сводится к изучению влияния независимой переменной (одной или нескольких) на зависимую переменную. Независимая переменная (Independent Variable) представляет собой качественно определенный (номинативный) признак, имеющий две или более градации. Каждой градации независимой переменной соответствует выборка объектов (испытуемых), для которых определены значения зависимой переменной. Независимая переменная еще называется фактором (Factor), имеющим несколько градаций (уровней). Зависимая переменная (Dependent Variable) в экспериментальном исследовании рассматривается как изменяющаяся под влиянием независимых переменных. В модели ANOVA зависимая переменная должна быть представлена в метрической шкале. В простейшем случае независимая переменная имеет две градации, и тогда задача сводится к сравнению двух выборок по уровню выраженности (средним значениям) зависимой переменной.
В зависимости от соотношения выборок, соответствующих разным градациям (уровням) фактора, различают два типа независимых переменных (факторов). Градациям (уровням) межгруппового фактора соответствуют независимые выборки объектов. Градациям (уровням) внутригруппового фактора соответствуют зависимые выборки, чаще всего повторные измерения зависимой переменной на одной и той же выборке.
В зависимости от типа экспериментального плана выделяют четыре основных варианта ANOVA:однофакторный, многофакторный, ANOVA с повторными измерениями и многомерный ANOVA. Каждый из этих вариантов дисперсионного анализа будет подробно рассмотрен далее в этой главе, а сейчас ограничимся их краткой характеристикой.
Однофакторный ANOVA (One-Way ANOVA) используется при изучении влияния одного фактора на зависимую переменную. При этом проверяется одна гипотеза о влиянии фактора на зависимую переменную.
Многофакторный (двух-, трех-, ... -факторный) ANOVA (2-Way, 3-Way... ANOVA) используется при изучении влияния двух и более независимых переменных (факторов) на зависимую переменную. Многофакторный ANOVA позволяет проверять гипотезы не только о влиянии каждого фактора в отдельности, но и о взаимодействии факторов. Так, для двухфакторного ANOVA проверяются три гипотезы: а) о влиянии одного фактора; б) о влиянии другого фактора; в) о взаимодействии факторов (о зависимости степени влияния одного фактора от градаций другого фактора).
ГЛАВА 13. ДИСПЕРСИОННЫЙ АНАЛИЗ (ANOVA)
ПРИМЕР______________________________________________________________
Предположим, изучается влияние на зрительскую оценку различных фильмов (зависимая переменная) двух факторов: жанра фильма (мелодрама, комедия, боевик) и пола зрителя. Вполне вероятно, что в результате такого исследования будут обнаружены не главные эффекты изучаемых факторов (влияние каждого из них в отдельности), а их взаимодействие. Взаимодействие факторов «жанр фильма» и «пол зрителя» будет означать, что мужчины и женщины по-разному оценивают фильмы в зависимости от их жанра (фильмы разных жанров оцениваются по-разному, в зависимости от пола зрителя).
ANOVA с повторными измерениями (Repeated Measures ANOVA) применяется, когда по крайней мере один из факторов изменяется по внутригрупповому плану, то есть различным градациям этого фактора соответствует одна и та же выборка объектов (испытуемых). Соответственно, в модели ANOVA с повторными измерениями выделяются внутригрупповые и межгрупповые факторы. Для двухфакторного ANOVA с повторными измерениями по одному из факторов проверяются три гипотезы: а) о влиянии внутригруппового фактора; б) о влиянии межгруппового фактора; в) о взаимодействии внутригруппового и межгруппового факторов.
Многомерный ANOVA (Multivariate ANOVA, MANOVA) применяется, когда зависимая переменная является многомерной, иначе говоря, представляет собой несколько (множество) измерений изучаемого явления (свойства).
Дополнительно выделяют модели ANOVA с постоянными (фиксированными) и случайными эффектами — различаются способами задания уровней (градаций) фактора. В модели с постоянными эффектами (Fixed Factors) уровни остаются фиксированными (одними и теми же) и при проведении данного выборочного исследования: как при обобщении результата на генеральную совокупность, так и при повторном проведении исследования. В модели со случайными эффектами (Random Factors) уровни фактора представляют собой более или менее случайную выборку из множества других возможных уровней данного фактора. Конечно, интерпретация (обобщение) результатов будет зависеть от используемой модели. При обработке данных различие между моделями в однофакторном ANOVA может не учитываться, но должно учитываться в двух- (и более) факторном ANOVA. В последнем случае результаты обработки для разных моделей будут различными. Допускается сочетание фиксированных и случайных факторов в одном исследовании.
ПРИМЕР______________________________________________________
Сравнивалась эффективность двух учебных программ. Для этого из нескольких сотен школ города было выбрано 5, а в них — по два параллельных класса, ученики которых обучались по разным программам. Исследование представляло собой реализацию двухфакторного плана с одним фиксированным (учебная программа: две градации) и одним случайным факторами (школа: пять градаций). Такое исследование позволяет проверить гипотезу не только об эффективности учебных программ, но и о том, будет ли различаться их эффективность в разных школах города.
ЧАСТЬ П. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
В случае, если фактор имеет более двух градаций, то подтверждение гипотезы о его влиянии позволяет сделать лишь неопределенный вывод о том, что по крайней мере две градации фактора различаются. Для более конкретного вывода о том, какие именно градации фактора различаются, в ANOVA предусмотрена процедура множественных сравнений (Post Hoc multiple comparison tests).
Во всех вариантах ANOVA наряду с изучением влияния факторов допускается изучение влияния метрической независимой переменной. Метрическая независимая переменная в этом случае называется ковариатой {Covariate), и дисперсионный анализ включает в себя ковариационный анализ.
Математическая идея ANOVA основана на соотнесении межгрупповой и внутригрупповой частей дисперсии (изменчивости) изучаемой зависимой переменной. Известно, что при объединении двух (или более) выборок с примерно одинаковой дисперсией, но с разными средними значениями дисперсия увеличивается пропорционально различиям средних значений этих выборок. Это связано с тем, что к внутригрупповой дисперсии добавляется дисперсия, обусловленная различиями между группами. В модели ANOVA внутригрупповая изменчивость рассматривается как обусловленная случайными причинами, а межгрупповая — как обусловленная действием изучаемого фактора на зависимую переменную. Соответственно, в общей изменчивости (дисперсии) зависимой переменной выделяются две компоненты: внутригрупповая (случайная) и межгрупповая (факторная) изменчивость. Чем больше отношение межгрупповой изменчивости к внутригрупповой, тем выше факторный эффект — тем больше различаются средние значения, соответствующие разным градациям фактора.
Нулевая гипотеза в ANOVA содержит утверждение о равенстве межгрупповой и внутригрупповой составляющих изменчивости и подразумевает направленную альтернативу — о том, что межгрупповая составляющая изменчивости превышает внутригрупповую изменчивость. Нулевой гипотезе соответствует равенство средних значений зависимой переменной на всех уровнях фактора. Принятие альтернативной гипотезы означает, что по крайней мере два средних значения различаются (без уточнения, какие именно градации фактора различаются).
Основные допущения ANOVA: а) распределения зависимой переменной для каждой градации фактора соответствуют нормальному закону; б) дисперсии выборок, соответствующих разным градациям фактора, равны между собой; в) выборки, соответствующие градациям фактора, должны быть независимы (для межгруппового фактора). Выполнение допущения о независимости выборок является обязательным в любом случае. Последствия нарушений остальных двух допущений требуют специального рассмотрения.
Нарушение предположения о нормальности распределения, как показали многочисленные исследования, не оказывает существенного влияния на результаты ANOVA (Шеффе, 1980; Гласе, Стэнли, 1977 и др.). Следовательно, перед проведением ANOVA нет необходимости в проверке соответствия выборочных распределений нормальному закону.
ГЛАВА 13. ДИСПЕРСИОННЫЙ АНАЛИЗ (ANOVA)
Нарушение предположения о равенстве (однородности, гомогенности) дисперсий имеет существенное значение для ANOVA в том случае, если сравниваемые выборки отличаются по численности. Таким образом, если выборки, соответствующие разным градациям фактора, отличаются по численности, то необходима предварительная проверка гомогенности (однородности) дисперсий. В компьютерных программах это осуществляется при помощи критерия Ливена (Levene's Test of Homogeneity of Variances). Если выборки заметно различаются по численности и дисперсии по критерию Ливена различаются статистически достоверно, то ANOVA к таким данным не применим, следует воспользоваться непараметрической альтернативой.
В основе современных программных реализаций дисперсионного анализа лежит представление о родственности дисперсионного и множественного регрессионного анализа: оба метода исходят из одной и той же линейной модели. В связи с этим, а также в связи с применением в дисперсионном анализе процедур и показателей, характерных для множественной регрессии, в последнее время все варианты дисперсионного анализа объединяются (например, в программе SPSS) под названием: Общая линейная модель (GLM — General Linear Model).
Параметрическими аналогами ANOVA являются такие многомерные методы, как множественный регрессионный анализ (глава 15) и дискриминант-ный анализ (глава 17). Отличие модели множественного регрессионного анализа заключается в том, что все переменные в ней, в том числе и независимые, представлены в метрической шкале. В модели дискриминантного анализа, в отличие от ANOVA, зависимая переменная является классифицирующей (номинативной), а независимые переменные — метрическими.
Непараметрическими аналогами ANOVA, как отмечалось, являются критерии //-Краскала-Уоллеса (для независимых выборок) и %2-Фридмана (для повторных измерений).
Вычислительные сложности, связанные с проведением ANOVA, представляли проблему до появления компьютеров и специальных статистических программ. Современные статистические программы (SPSS, STATISTICA) избавляют пользователя от утомительных расчетов. Однако понимание и правильная интерпретация получаемых показателей обязательно требуют наличия общего представления о том, как они вычисляются. Поэтому изложение основных методов ANOVA будет сопровождаться демонстрацией расчетов на упрощенных примерах, которые будущему пользователю компьютерных программ желательно внимательно изучить.
ОДНОФАКТОРНЫЙ ANOVA
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ Математическая модель однофакторного ANOVA предполагает выделение в общей… Нулевая статистическая гипотеза содержит утверждение о равенстве средних значений. При ее отклонении принимается…Условие 122
Условие 1 Условие 2 Условие 3 № У № У № У …Обработка на компьютере
1. Выбираем Analyze > Compare means> One Way ANOVA... 2. Воткрывшемся окне диалога выделяем и переносим из левого окна пе ременные при помощи кнопки >: зависимую…Descriptives VOSPR
Первая колонка — номера градаций фактора, вторая колонка (N) — численность выборок, Mean — средние значения, Std. Deviation — стандартное… ЧАСТЬ И. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ В) Проверка однородности дисперсии:МНОЖЕСТВЕННЫЕ СРАВНЕНИЯ В ANOVA
Методы сравнения средних после отклонения Но об отсутствии различий предназначены для выделения тех пар средних, которые привели к отклонению Но.… При использовании метода Шеффе достоверность различия средних значений…Обработка на компьютере
Повторим все операции, которые мы совершали для проведения однофак-торного AN OVA: 1. Выбираем Analyze > Compare means> One Way ANOVA... 2. Воткрывшемся окне диалога выделяем и переносим из левого окна пе ременные при помощи кнопки >: зависимую…Scheffe
1.00 5.0000 … Means for groups in homogeneous subsets are displayed. a Uses Harmonic Mean Sample Size = 5.000.СС — СС -I- CC 4- ОС
Суммы квадратов для фактора A (SSA) и фактора В (SSB):
-.2
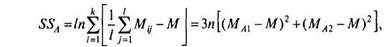
N[(Mm-M)2 +(MB2-M)2+(MB3-M)2].
fA dfB dfAB dfwg Вычисляются эмпирические значения F-отношения для каждой из трех проверяемых гипотез:– Конец работы –
Используемые теги: Введение, проблему, статистического, вывода0.079
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?
Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.157 сек.
Новости и инфо для студентов